
January 15, 2016 (Vol. 36, No. 2)
“Sharing information is key, and we have to share detailed phenotype information—not just the published paper, but also the clinical data and the profiling data,” insists Sek Wong Kong, M.D., assistant professor, Boston Children’s Hospital.
Clinical information is available from electronic medical records (EMR), and profiling information is available from patient samples. Yet sharing these kinds of information is still difficult.
“Finding datasets made by someone else is a big challenge,” Dr. Kong complains. “We need to change that. Otherwise, we are underutilizing our biosamples and patient information.”
One challenge to implementing change in biorepositories is protecting personal health information (PHI) and protecting patient identities while simultaneously building a highly annotated specimen bank. The systems built to enable information sharing “must be able to pull in data in a way that protects PHI,” emphasizes Maureen Lane, Ph.D., a clinical development scientist at ExecuPharm who is on assignment at Merck.
Sample tracking and quality assessment is another key biobanking challenge, and “you have to be very respectful of the fact that the clinical diagnosis comes first,” reminds Sandra Gaston, Ph.D., scientific director, Tufts Medical Center Biorespository. “Whatever you are doing in terms of collection, research must always come second to the diagnostic requirements.”
Drs. Kong, Lane, and Gaston were among the speakers at IIR’s Biorepositories and Sample Management Summit recently held in Boston. Their contributions to this event are reflected in this article, along with other highlights, which range from industry trends to innovative projects to sample quality/control methods.
Paradigm Shift
“Next-generation biobanking is a term I began seeing used on social media and in the field about two to three years ago,” says Lisa B. Miranda, president and CEO, Biobusiness Consulting.
Although there is probably not any formal definition of the term, Miranda says that next-generation biobanking “implies a paradigm shift from conventional operational management of biobank facilities to integrative prospective, strategic, and scientific approaches to data and sample management.”
This shift is driving real-time delivery of cutting-edge results and new evidence-based scientific insights, which is essential for supporting precision medicine initiatives.
Upstream Quality Assurance
“The Biospecimens Accessioning and Processing Core Laboratory is a preanalytical lab within the Mayo Clinic’s Biorepository Program,” says Mine Cicek, Ph.D., the Biorepository Program’s director. The samples processed by the laboratory, such as DNA samples from whole blood, can be sent to downstream laboratories for applications such as next-generation sequencing.
“If something doesn’t work, the downstream lab may check the quality of the samples to figure out if the problem is the sample or their technology,” she explains. The idea is to create a feedback loop that enables everyone to continuously learn about the nuances of sample integrity for ever-evolving technologies.
“Our goal is to process and store samples the right way, so there is no question about their quality when they are used for downstream analysis,” she emphasizes. Getting quality work done is an outcome of optimizing and standardizing laboratory procedures.
Asking principal investigators the right questions is critical for setting up studies in the laboratory’s automated LIMS (laboratory information management system). For example, principal investigators should be asked what kind of tubes they use to collect their samples. Such a question, she points out, could ensure that “the automation will aliquot samples in the right robotic-friendly matrix tubes for storage in the robotic freezers.
“Our LIMS tells us what to do with every sample,” she continues. “We support hundreds and hundreds of studies, and everyone wants something different.”
Every study is IRB (institutional board review) approved, and there’s a principal investigator who functions as a steward for that collection. Collections can be shared. An investigator wanting to use samples from another manager’s biobank can go through IRB to secure the necessary approval. “That’s how we give access to samples to a different principal investigator,” notes Dr. Cicek.
At the Mayo biobank institutional collection, which includes samples from 50,000 individuals, protocols are reviewed and access requests are decided by an external advisory board and an internal access committee.
Dr. Cicek emphasizes that the Mayo biobank “has the infrastructure, including the logistics and standardization, to meet the stated goals of President Barak Obama’s Precision Medicine Initiative to biobank samples from one million individuals.”
Tissue Prints for All Comers
Tissue prints provide a practical method for collecting oriented, snap-frozen samples from all levels of a specimen without compromising the tissue for surgical pathology. “Simply take nitrocellulose, touch the fresh tissue, and you get about a monolayer of cells,” explains Dr. Gaston. Voilá! “You’ve taken a little transfer print of the specimen.”
The tissue print sample consists of both cells and extracellular matrix, and the tissue architecture is reflected in the print “image” on the nitrocellulose.
When the nitrocellulose blot is snap-frozen, the “nucleic acids are beautifully preserved,” she details, making issue prints ideal for biomarker studies incorporating array- and sequence-based profiling techniques.
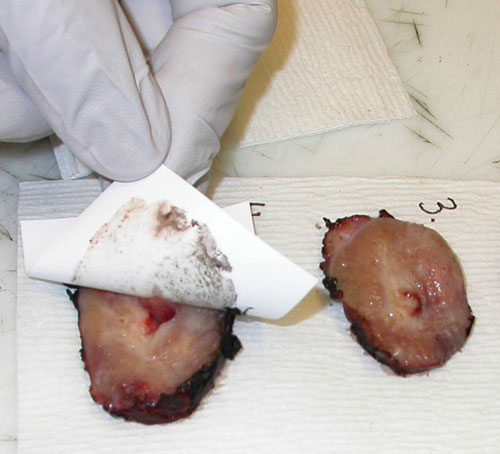
“Recently, in an innovative DOD-funded study focusing on prostate cancer in African Americans, our multicenter team used DNA and RNA isolated from tissue prints collected prospectively from needle biopsies to identify cancer subtypes that had not previously been recognized,” Dr. Gaston says. “If you only use radical prostatectomy material from a conventional biobank, you miss one of your most important patient subgroups, individuals whose cancer is so advanced they are going to see the oncologist and not have a prostatectomy.”
Tissue prints allowed the team to focus on the biopsies and look at a group of patients that had not been well studied before.
“I think tissue printing is going to find a niche as a source of high-quality RNA and DNA that you can use for molecular testing in a clinical context as well as in research,” Dr. Gaston predicts. “This technology is not something so novel that only a few places can do it. It’s easily adoptable by other groups. If folks would like a demonstration, we are very happy to share what we have learned.”
Strategies for Prospective Applications
When Dr. Kong and colleagues started the autism biomarker study in 2006, few unbiased profiling technologies were available, with the exception of gene-expression profiling. “Now we are living in a world where we can perform unbiased screens for multiple factors all at once,” he exclaims. Unbiased approaches are helping to elucidate factors associated with autism besides those due to the brain.
It’s a challenge to anticipate sample collection needs for prospective applications. One way to meet this challenge, suggests Dr. Kong, is to “preserve all of the biomaterial that can be obtained noninvasively.” Other investigators are collecting urine and fecal samples for microbiome studies, which are “the next big thing,” he adds.
“Patient-derived induced pluripotent stem cells and fibroblasts are essential research tools for the biobank of the future,” he states. He likens their importance in precision medicine to HeLa cells in elucidating fundamental cellular processes in cancer.
Mining the Vault, Privacy First
“Initially, when biobanks started, samples were completely de-identified,” Dr. Lane recalls. One might have known that a particular sample was a lung tumor, but important information—tumor type, for example, or treatments to which the tumor had been exposed—would not have been available.
“Now the problem is there are tens of thousands of biosamples available in our hospitals, but the clinical phenotypes are not readily available,” laments Dr. Kong. “We cannot search EMRs without approvals. This poses a problem for research.”
Perhaps there is information about a drug for a certain cancer, that is, a cancer associated with a certain mutation, that would be more meaningful if it could be combined with sequencing and treatment data from another disease. The ability to search databases for actionable mutations might identify an existing drug or an available clinical trial that may be effective in treatment.
Typically, EMRs collect clinical data and other systems collect biorepository data. “It’s a challenge to de-identify EMR data and then marry it to clinical samples,” confirms Dr. Lane. Many institutions are actively working on this problem.
Dr. Kong adds that “EMRs could be de-identified using natural language processing (NLP).” For instance, IBM Watson already uses NLP and machine learning to reveal insights from big, unstructured datasets. “[But] I don’t think it’s connected to biobanks yet,” Dr. Kong sighs.
Complicated systems are being brought together in ways that protect people, offer comprehensive information, and enable researchers to log in and mine data. This kind of integration, however, necessitates more inclusive, broader patient consent forms. These are still being developed.
“Currently, clinical use of data is not a problem; it’s sharing for research use, which is regulated by IRB,” informs Dr. Kong. “By 2020, most national biobanks should have de-identified information that is still detailed enough to use, and that’s the expected timeline for merger integrations between EMRs and biorepository systems.”
Cost containment is essential too. Dr. Kong remarks that “detailed phenotyping costs significantly more and is more labor intensive compared to genomic characterization efforts such as whole-exome sequencing.”
Open Access Population Biobanking
“Although we are living longer, we are also treating people longer who have chronic illness,” says Suzana Anjos, Ph.D., the data access and business development manager at CARTaGENE, a research platform of the CHU Sainte-Justine. “We are doing so without really understanding underlying disease mechanisms and disease causes, which may be different among different people and populations.”
Elucidating the effects and interactions between genes and environment on disease remains a formidable challenge. As part of a global push to understand chronic disease, the CARTaGENE population-based biobank cohort has been set up to capture information about people’s health and lifestyles.
“We have a core health and lifestyle questionnaire that’s been harmonized across Canada, and with other large cohorts as well,” continues Dr. Anjos. Multiple factors are involved in chronic illness, so harmonizing across large numbers of people is important for elucidating meaningful associations.
The CARTaGENE project includes standard cognition assessments, detailed physical measurements, and biochemical analyses of blood samples from participants. Some of the blood earmarked for DNA analysis is stored in 384-well GenPlates, whereas blood for RNA work is collected in Tempus tubes.
“We had a researcher working on a project looking at the effects of a herpes viral insertion on the population,” recalls Dr. Anjos. “He needed only one GenPlate well from each of 20,000 different individuals to successfully perform PCR for a region.”
The CARTaGENE cohort is an open-access, data-sharing population biobank with very deep phenotype data among various cohorts, including detailed nutritional data.
“Any researcher with a health-related project from academia or industry can request access to the datasets and samples by providing required documents, such as project proposals and ethics approvals,” Dr. Anjos emphasizes. “An independent committee reviews applications and approves access. We are very happy to send out aggregate data so researchers can write their grants and hopefully use the samples and resources as much as possible.”
“There are huge groups of patients that want to get actively involved in research, but they don’t know how to proceed,” concludes Dr. Kong. He expects that in the future, through venues such as the PCORI (Patient-Centered Outcomes Research Institute) programs, patient groups will have increasing opportunities to drive research, collect their own biosamples, and help establish biorepositories for their specific diseases.
Factors influencing disease onset are dependent on genetics as well as the interaction of genetics with the environment. Population-based biobank cohorts that gather information about environmental exposures, be it atmospheric pollution, stress at work, or lifestyle stressors, are critical to understanding the trajectories of chronic disease and formulating multidisciplinary approaches to tackling these diseases. [CARTaGENE]
Genotyping Large Populations
Many of today’s biobanks are undertaking large-scale epidemiological genotyping studies. For example, the U.S. Department of Veterans Affairs is in the midst of its Million Veteran Program, which will study selected genetic variants on up to one million veteran volunteers.
Another large program, the UK Biobank Genetics Analysis Project, has collected and recently genotyped samples from 500,000 individuals on over 800,000 markers. These cohort studies demand flexible, robust, high-throughput sample processing and bioinformatics analysis workflows capable of producing a large amount of high-quality genotyping data.
Single nucleotide polymorphism (SNP) arrays have been used as genetic analysis tools for these studies due to their high SNP content density and economical genome-wide interrogation of genetic variation along with easier data analysis. An Affymetrix official notes that their Axiom® genotyping solution has been selected as the preferred platform by many of these large biobank projects due to its fast time-to-result, throughput, data consistency, and cost profile.
“Leveraging Affymetrix’s expert and collaborative bioinformatics design capability, investigators can rapidly customize Axiom arrays to meet the specific epidemiological objectives of the project, either from de novo informative content or pre-existing content modules, with no SNP dropout, for maximum data completeness,” says Laurent R. Bellon, Ph.D., senior vp and general manager, genetic analysis business unit and global operations.
Preserving Sample Integrity & Security
Managing, tracking, and storing the thousands, sometimes millions, of samples that are collected in a biobank is a huge challenge, as is maintaining the integrity and quality for the life of those samples. The traditional method of manual storage in freezers is no longer up to the task. Sample degradation is a serious possibility with manual freezers as samples are retrieved and re-stored. Freezer doors are opened, creating temperature variations that can compromise sample integrity. Improper placement of sample racks in the freezer also can lead to significant variation in the samples’ internal temperatures.
Finding and cataloging samples within one or more freezers is time-consuming and challenging, and these records are prone to human error. Security and access controls are additional major factors to consider in sample management and storage.
An advanced automated sample management system, such as the Hamilton BiOS, can handle multiple types of labware simultaneously to streamline processes from input to retrieval to re-storing while maintaining sample integrity and security and chain-of- custody documentation, according to Matt Hamilton, president of Hamilton Storage.
“The system also can interface with robotic sample processing workstations for a fully automated biobanking workflow,” he adds.
Lisa Heiden Ph.D. is director of business development at MyBioSource.

