
June 1, 2016 (Vol. 36, No. 11)
Big Data’s Influences Range from the Sequencer to the Clinic
If you want to summarize the essentials of an activity or discipline, try an alliterative list, such as the “three R’s” or the “five D’s.” These examples, which pertain to education and dodgeball, respectively, come from popular culture. Alliterative lists are found in science, too.
For example, according to genomics pioneer Leroy R. Hood, personalized medicine comes down to the “four P’s”—Personalized, Proactive, Predictive, and Preventative. And where would personalized medicine be without Big Data, which brings evidential scope and analytical depth? Big Data itself is all about the “four V’s”—Velocity, Volume, Variety, and Veracity.
The four V’s come together under certain conditions. The condition of size is essential, of course, but insufficient. The four V’s do not occur with every large dataset. They are reserved for continuously evolving, multidimensional datasets that require real-time processing. In such datasets, information is continuously collected from sensing devices and analyzed in real time. In fact, multiple information streams may be processed in parallel.
Even whole-genome sequencing may not qualify as “big” in the Big Data sense, even though it requires terabytes of raw and processed data. To attain Big Data status, whole-genome sequencing must become integrated with other omics, clinical, behavioral and/or environmental parameters.
Big Data, which consists of platforms that are as diverse as they are sophisticated, can be an overwhelming subject, especially if one is trying to stay up to date technologically. Yet Big Data can seem more comprehensible if one stays laser-focused on the utility question: How will Big Data improve people’s lives?
Values and Value Propositions
At Teva Pharamaceutical Industries, the mastery of Big Data is viewed not only as a means of reinforcing the firm’s social license to operate, but also as a tremendous opportunity for seizing competitive advantage. Teva believes that Big Data, like any other new technology or capability, is valuable to the extent that it uniquely and effectively serves a worthwhile purpose.
In the case of Big Data, the value proposition is a matter of applying the technology to the right scientific questions. Such questions should be amenable to Big Data’s evidence-based approach, and they should, upon being answered, lead to the satisfaction of unmet needs.
“When we run a study for Huntington disease or another neurodegenerative disease with a dominant movement disability, we approach the patients, their families, and their caregivers,” says Iris Grossman, Ph.D., Teva’s vice president and head of personalized and predictive medicine and big data analytics. “We identify and address the pharmacological needs, we characterize the genetic and biomarker features of patients, carriers and responder populations, and we employ sensing tools, all of which collectively aim to monitor and improve debilitating symptoms and disease progression.”
“This represents a holistic approach to health management,” Dr. Grossman continues. “It is designed to touch the lives of patients from early presymptomatic stages all the way through to polypharmacy and beyond-the-pill solutions. It is expected to evolve as we refine our understanding of unmet needs.”
Big Data means a new pace of information flow and a new level of access and sharing. It will encourage the pharmaceutical industry to start operating as a network of R&D organizations, and it will enhance collaborating across industries.
Big Data also opens up the door for everyone to become truly engaged in the management of their health and their families’ wellness needs. As data accumulates, the scientific population will be able to derive increasingly accurate insights.
Data-Driven Research
A move toward value-based medicine increases the pressure to discover and develop therapeutics in more economical and efficient ways. To relieve this pressure, researchers may resort to Big Data. However, if researchers are to derive actionable outputs from Big Data applications, they will have to integrate Big Data with a range of research activities.
“Data is easy to store and manage,” says Slava Akmaev, Ph.D., chief analytics officer, Berg. “The bottom line is what you do with it.
“We generate data by looking at the biology of the patient from a very systematic perspective of contrasting disease versus health. We know the type of data that needs to be generated beforehand and study it in the context of the biology under investigation. Our entire pipeline was discovered using this approach.”
Berg begins by using human in vitro models, both cells and tissues, to model disease. Perturbations are introduced to interrogate the system in a manner similar to the natural physiological conditions of the disease state. Then Berg applies its datasets, which encompass genomic, lipidomic, metabolomic, and proteomic information, as well as information about post-translational modifications.
All the data are funneled into a proprietary artificial-intelligence (AI) platform, Interrogative Biology, to identify major drivers of disease, information that can be rapidly transitioned for validation in wet labs. Patient-specific molecular data, along with data from medical records and phenotypic data, can be superimposed with the classical research data.
Berg hopes that the Interrogative Biology platform can be used to develop a comprehensive understanding of cancer, one that would tie together cancer’s underlying biology and its phenome-level manifestations. The company says that the platform’s combination of adaptive-omic biological data and AI machine learning algorithms allows it to stratify patient populations by phenotype to build predictive models. For an individual patient, a model can be applied to clinical information to predict the efficacy of a drug or screen out potentially toxic treatments.
Two endogenous molecules to emerge from the AI platform are in clinical trials—31510 for advanced refractory solid tumors, and 31543 for topical alopecia. A diabetes assay is under development as well as biomarker panels for neurological diseases, such as Parkinson’s and Alzheimer’s disease.
“All assets are ‘first in class’ and ‘first in kind,’ and our batting average is high,” declares Rangaprasad Sarangarajan, Ph.D., Berg’s CSO. “The combination of biological data, pan-omics, and AI generates the hypotheses, and all discoveries are based on human sources.”
Berg is confident that this approach can put biological metrics in the context of human disease. Moreover, according to Dr. Sarangarajan, this approach can “speed up the cycle from discovery to clinic.”
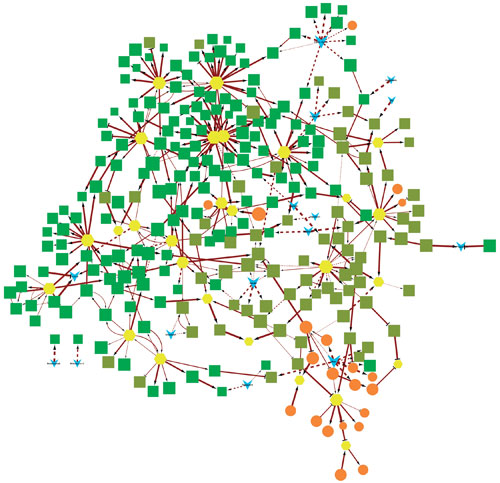
Interrogative Biology, Berg’s artificial intelligence platform, is a data-processing instrument for generating actionable hypotheses. It subjects multi-omics data to analysis using a Bayesian network inference approach, and it can infer cause-and-effect relationships for each analyzed condition. In this image, a multi-omic map of metastatic cancer is shown. Besides confirming known interaction pathways, such maps may also identify new and physiologically relevant molecular interactions.
Search and Analytics
Pharma needs to speed up the submission of new drug applications, to reduce costs for new drug development, and to make educated decisions to continue or stop trials based on clinical trial data. This constitutes a data deluge that Big Data search and analytics platforms can help resolve.
Once such platform is available from Sinequa. The company has developed Sinequa ES, which combines statistical analysis of structured data with linguistic and semantics analysis of texts in 20 major languages. Sinequa says that its platform has strong natural language processing (NLP) capabilities.
Advanced natural language processing can provide deep visibility into massive volumes of complex data and provide the insights needed to speed drug time-to-market or to make informed decisions about clinical trial effectiveness. Using artificial intelligence and machine-learning algorithms on Apache Spark, an open-source processing engine, Sinequa ES can provide statistical analysis of data and combine both statistical and linguistic/semantic data in the analysis for a complete view.
Furthermore, Big Data search and analytics solutions can provide researchers with unified access across an organization to all structured and unstructured data from both internal and external sources. This can drive innovation, accelerate research, and shorten drug time-to-market while fostering cooperation in R&D and respecting information governance and security.
“When it comes to Big Data search and analytics, it is definitely not a one-size-fit-all approach,” states Laurent Fanichet, Sinequa’s vice president of marketing. “Every company has different requirements. Companies have different data sources they want to index, both internal and external, and diverse user profiles.”
By leveraging advanced NLP along with universal structured and unstructured data indexing, Sinequa’s platform enables customers, such as AstraZeneca, Biogen, Bristol-Myers Squibb, and UCB, to achieve critical in-depth content analytics and establish an agile development environment for search-based applications (SBAs).
The real-time Big Data search and analytics platform is used to identify networks of experts and key opinion leaders, find the most suitable scientific partners, automatically provide researchers with the latest scientific information in their fields, access and discover research trends, deliver information on drugs and diseases (starting from chemical structures), and provide an enterprise-wide information portal.
The platform features a multilingual search engine, deep-content analytics with high performance and out-of-the-box connectivity to more than 150 enterprise, and cloud applications and other data sources.
Accessing unstructured datasets, integrating data from multiple sources and working collaboratively with other departments and organizations will continue to be challenges moving forward. Organizations will need to handle more digital content and billions of documents and records, making agility and scalability prime considerations.
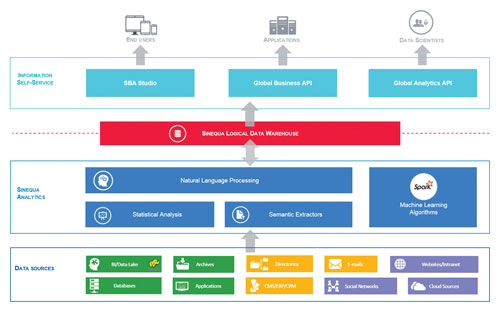
Sinequa’s ES search and analytics platform is meant to provide comprehensive unified information access. As this system architecture diagram indicates, the platform incorporates natural language processing along with structured and unstructured data indexing. It also has a connector library and a user interface that can be used to facilitate the rapid development of search-based applications. In the life sciences, the platform may be used to foster cooperation in drug development efforts by identifying suitable partners and facilitating information exchanges.
Investing in Data
Investing in a data-management strategy is growing in importance, as data volumes grow exponentially, and the variety of data and how it is parsed to provide meaningful insights changes with technology adoption.
Pharma is notoriously data-intensive. It has reams of data that include clinical trial data, structured and unstructured electronic medical records, lab test results, and claims data. Genomic and wearables data (Internet of Things, IoT) adds another dimension. Parsing the information becomes more critical as data become more heterogeneous.
According to Sagar Anisingaraju, chief strategy officer, Saama, the first and most crucial step in addressing data challenges is a sound strategy to integrate disparate data sources into a single repository, a data lake, to aggregate, manage, clean, and stage data for consumption. This foundational element is essential for enabling predictive, real-time, and prescriptive analytics.
Anisingaraju also stated that the ability to effectively capture and manage data at all stages of the value chain—discovery, clinical trials, regulatory approval, marketing, anddistribution—is essential for companies to derive maximum value.
Saama’s life sciences offerings, Clinical Development Analytics (CDA) and Real World Evidence Analytics (RWEA), bring together a mix of domain-data expertise, innovative technology assets, and business-relevant metric insights. The applied suite of analytics provides prebuilt visualizations, tools, and applications that facilitate the proliferation of real-world uses, and that enable researchers to accelerate evidence generation.
CDA offers risk-based monitoring of clinical operations for cost-effective clinical trials through better anticipation of delays and early risk mitigation, developmental analytics for instant insights through automation of manual statistical analysis of clinical trials data, and contract management analytics for improved analysis of vendor bids and performance.
RWEA provides a suite of prebuilt capabilities that enable users to identify specific populations of patients based on demographics that exhibit specific characteristics to determine unmet medical needs in order to better target the right drugs for specific cohorts of patients.
The products allow users to manage, analyze, and turn information into actionable insights; leverage volumes of data and complex data types into scientifically relevant insights; improve operations management across the enterprise and a complex regulatory environment; and understand hidden trends.

