
Sponsored content brought to you by
![]()
To reach the full potential of genomics in healthcare, researchers need to manage exponentially growing amounts of data as well as advanced systems in which they can easily analyze it. The landscape of genomic data analysis is becoming more complex due to the richness and large volume of data available. We are entering the analytics-driven phase of the genomics revolution, and Illumina is meeting the challenge with its comprehensive bioinformatics platform.
When the company’s NovaSeq™ 6000 was released in 2017, it immediately raised the bar on genomic sequencing because of its capacity to sequence up to 48 human whole genomes per run on a single instrument. Sequencing one genome alone can generate up to 6 terabytes and 20 billion reads.1 Now, whole-genome and -exome sequencing are becoming commonplace, and the primary emphasis is on analytic tools to maximize the insights drawn from the mountains of data being generated.
The data complexity conundrum drives the need for artificial intelligence (AI) decision-support tools. Simply put, AI programs enable computers to learn and recognize patterns in vast amounts of data. Although human oversight may be required to come up with a workable model, AI is designed to also work alone, especially when data volume makes direct human analysis unfeasible.
AI works best based on thousands of samples and really takes off when input reaches tens or hundreds of thousands of samples. As data sets continue to grow in richness and volume, AI becomes even more critical to quickly extract relevant findings that might otherwise be overlooked.
Information in multiple dimensions
Samples are a collection of information in multiple dimensions, such as imaging data, ”omics” data, and phenotypic data, such as data from electronic medical records (EMR). For example, in many countries, biobank projects collect and standardize patient data over a period of time and provide access to these large sets of data for use in target discovery and other applications.
Standardizing and combining different dimensions is a complex endeavor. AI determines patterns, clusters, and characteristics in the different sources of data, unperceived from a human perspective, to enable actionable insights for users to further their research or to support decision making. The broader the data, the higher the probability of a high-quality, targeted result.
To help researchers accelerate genomic understanding, Illumina developed analytics platforms to complement its sequencing tools. “Our integrated bioinformatics platform is now generating as much interest as our sequencing tools have done since we first launched them,” says Rami Mehio, Illumina’s Vice President of Software and Informatics Product Development.
The challenge is clear. Genomics researchers have long spent more time struggling to integrate and upgrade their analytical tools than doing actual sequencing. For some tasks, just finding the optimal solution can be a major hurdle. Furthermore, researchers want better tools to aggregate data and easily share it. That is why Illumina decided to develop the full range of necessary tools that can be bundled together to address the needs of their wide range of genomics customers.
The platform
Illumina Connected Analytics (ICA) is a modern cloud-based platform, deployed on Amazon Web Services (AWS). ICA enables complex analysis and discovery in a secure, compliant environment and is further enhanced with research-oriented extensions.
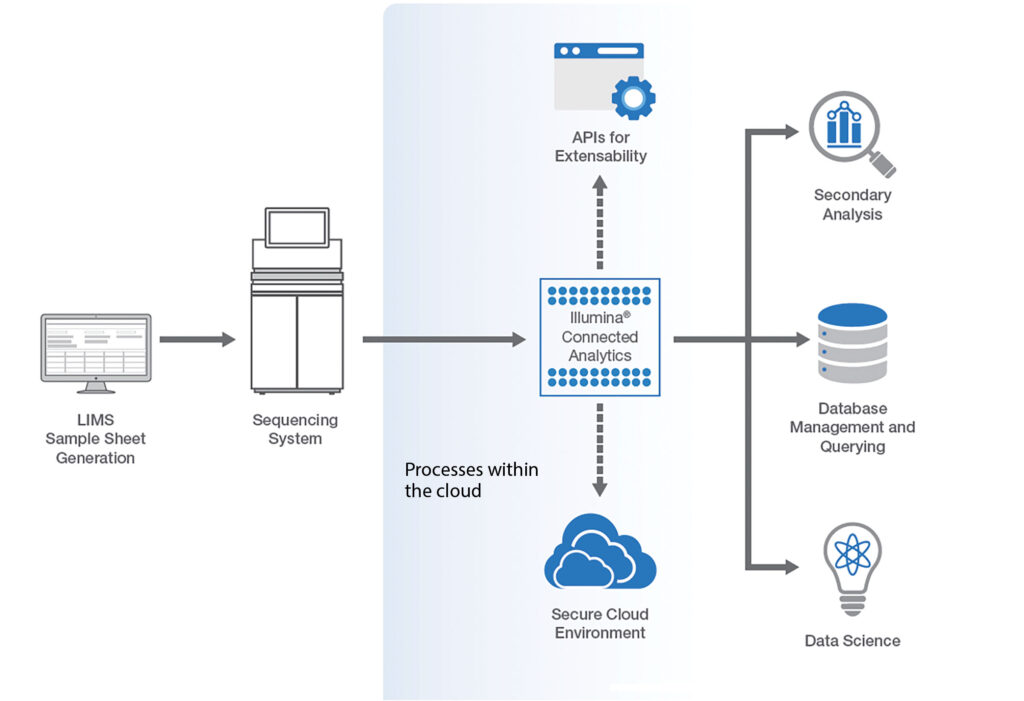
Additional capabilities include the ability to manage sequencing runs and laboratory workflows, perform accurate and fast secondary analysis, aggregate data from a wide range of sources, and complete tertiary analysis via a range of tools.
Led by Professor Sean Grimmond, PhD, the University of Melbourne Centre for Cancer Research (UMCCR) is working to accelerate improved outcomes for cancer patients by using genomic information to understand cancer development and target therapies. The UMCCR collaborates with Victorian Comprehensive Cancer Centre (VCCC) Alliance partners to enable personalized cancer care programs across institutions.
The goal of UMCCR’s Genomics Platform Group is to improve “the scalability and reliability of sequencing workflows, better detect changes in cancer genomes, and make tumor data accessible in real time.” To help achieve this outcome, Oliver Hofmann, PhD, Associate Professor and Head of Bioinformatics, Clinical Pathology at UMCCR and the leader of the Genomics Platform Group, partnered with Illumina to gain early access to ICA.
The team wanted to increase scalability by migrating from traditional high-performance computing (HPC) to a cloud-based platform. The platform had to be open, cloud-native, easily accessed by the labs that would ultimately use the provided workflows to analyze and interpret data on their own, and responsive to applicable standards. Fast bioinformatics were imperative to enable labs to go from genome to report in less than seven days.
Using ICA, users can access any public workflow and easily share their own workflows with others, simplifying collaboration. The platform was architected to allow for robustness and extensibility, including modifications to meet unique needs.
“Moving everything to one environment minimizes the processes that we have to vet for each new workflow and simplifies the accreditation process, which, in turn, supports setting up a clinical sequencing environment,” states Hofmann. “It streamlines processes and enables us to leverage work that has already been done, so we are not constantly redoing the same proof work.”
In addition, ICA offers the power of the DRAGEN™ Bio-IT Platform for accurate, ultra-rapid secondary analysis of sequencing data. Using the DRAGEN pipelines, a whole-genome tumor/normal analysis can be completed in about 6 hours, and the overall time for secondary analysis (QC, germline, somatic, post-processing) is now reduced to 20 hours.1 This speed is crucial; to go from genome to curated report in 7 days. “The gains in turnaround time are impressive,” says Hofmann.
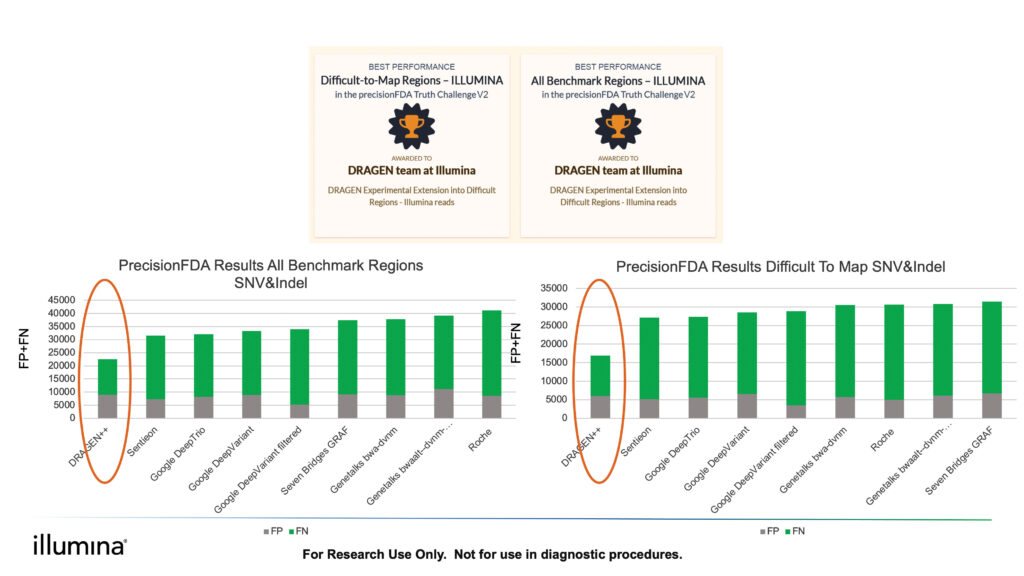
To achieve your AI goals, you need to build the most sensitive and accurate models. In August 2020, the DRAGEN mapper + small variant caller won the PrecisionFDA challenge V2 accuracy2 contest for Illumina reads in the Difficult-to-Map Regions and All Benchmark Regions categories, with 38% and 28% fewer call errors than the second-best contestants, respectively. DRAGEN also offers robust structural variant, copy number variations, and repeat expansion callers and can process germline, somatic, and RNA data.
Growing with the needs
The number and types of health-related public data sources continue to grow at a dramatic speed, offering a larger volume of data with more breadth to genomic researchers. The next wave of genomic studies will include more diverse populations, better powered analyses, and questions about parts of the genome that may never have been studied in detail before.
Illumina scientists concur that building a complex exploration and analysis environment can be a daunting task, especially in a field in which the data, tools, and understanding evolve as fast as is the case with genomics. A good foundation is essential for success.
The company is committed to staying abreast of the fast-moving field of bioinformatics. “Thanks to our many partnerships like the one with UMCCR, Illumina has a clear view of the trends that are advancing genomics,” says Mehio.
References
1. Data calculations on file. Illumina, Inc. 2021.2. PrecisionFDA Truth Challenge V2: Calling Variants from Short and Long Reads in Difficult-to-Map Regions.



